2020. 3. 29. 22:01ㆍArtificial Intelligence
본 포스팅은 cs231n의 강좌를 정리한 글임을 서두에 밝힙니다.
캡쳐된 일부 강의 자료들은 CS231n에서 제공하는 PPT 슬라이드를 참조하였습니다.

Definition
이전 포스팅에서 컴퓨터 비전 분야의 주된 과제 중 하나가 Image Classification 이라고 설명하였습니다. Image Classification 모델은 컴퓨터에게 인풋 이미지를 제공하면 그 이미지가 가지고 있는 개체의 이름(Label)을 출력합니다. 이를 수행하기 위해 다량의 데이터를 이용하여 컴퓨터를 학습시키는 "Data-Driven Approach"가 주로 사용되는데, KNN은 그 방법 중의 하나입니다.
KNN은 굉장히 간단한 알고리즘입니다. KNN이라는 이름의 뜻 자체가 (K - Nearest Neighbor)이라는 뜻인데, 말 그대로 입력 받은 이미지와 비슷한 (일반적으로 픽셀 값의 차이의 합이 가장 작은) K개의 이미지를 찾아서, 그중에서 가장 많은 수를 차지하는 이미지의 label을 출력값으로 하는 방법입니다. 예를 들어 아래의 그림에서 빨간색 세모는 강아지, 파란색 네모는 고양이라 하고, K 값을 5로 설정했을 때, 가까운 5개 중에서 고양이가 차지하는 개수 (논문에서는 Vote라고 표현합니다.)가 더 많기 때문에 고양이라고 판단하는 것입니다.
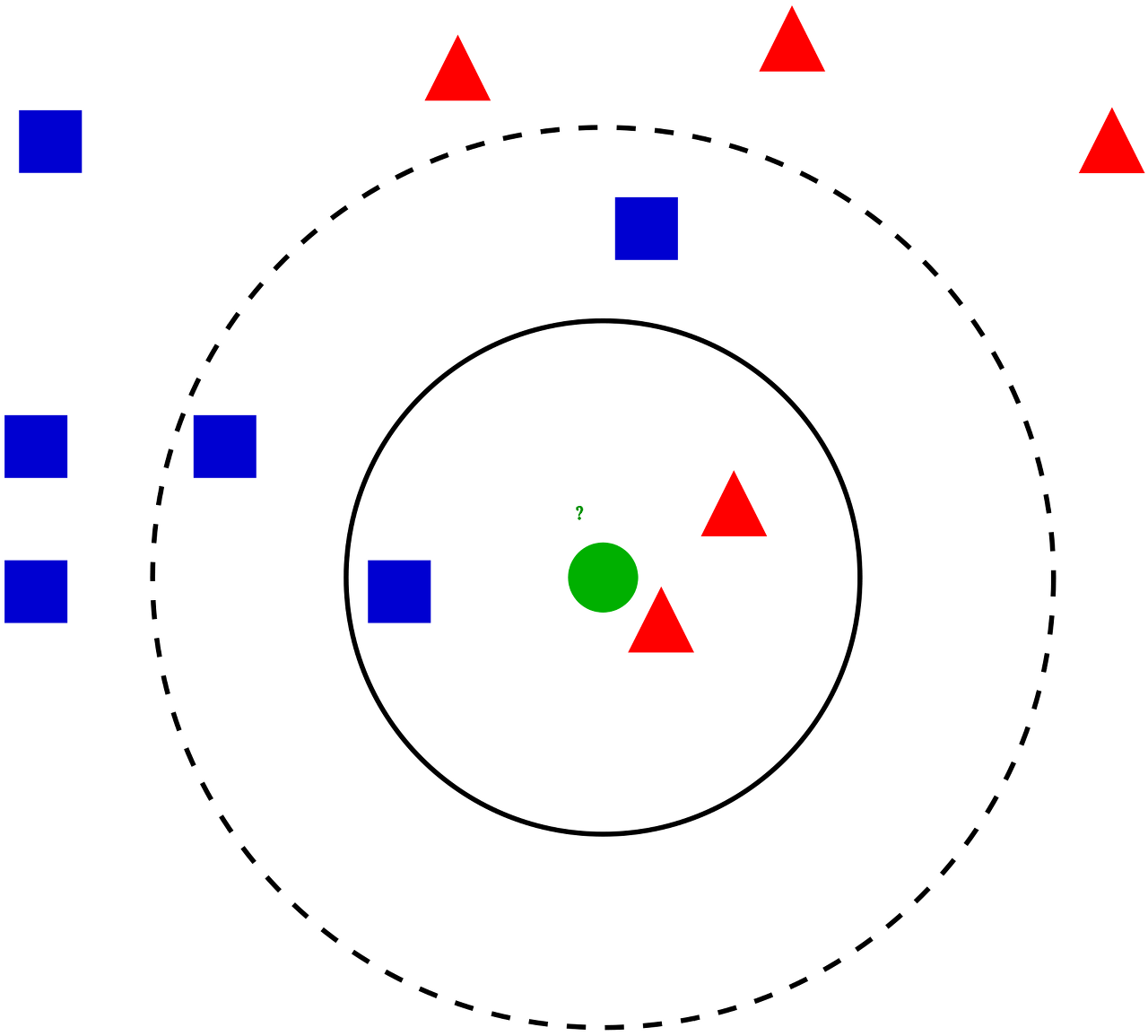
Hyperparameter
KNN알고리즘의 원리는 간단하지만 KNN을 구현하고 또 어느 수준 이상의 정확도를 보여주기 위해서는 몇 가지 고려해야 할 사항이 있습니다. 크게 "두 이미지의 비슷한 정도를 어떻게 구분할 것인가?" 와 "K는 어떤 기준을 가지고 잡아야 하는가" 입니다.
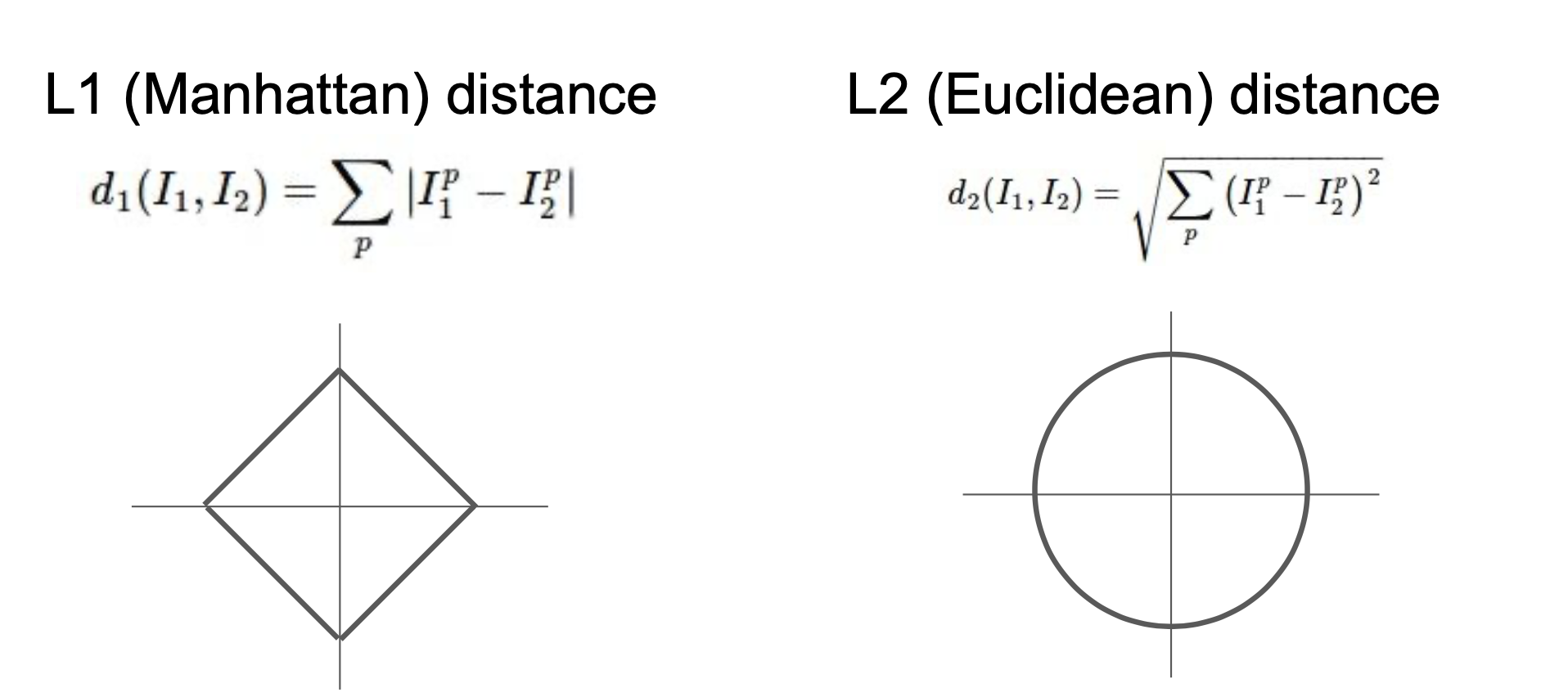
이미지의 비슷한 정도를 나타내는 척도로는 흔히 L1 norm, L2 norm을 사용합니다. L1 norm은 맨해튼 거리 라고도 불리는데, KNN 알고리즘에서는 단순히 두 이미지의 픽셀 값의 차를 절댓값 처리한 후에 다 더해서 나타냅니다. L2 norm은 유클리드 거리 라고 알려져 있는데, 두 이미지의 픽섹 값의 차를 제곱해서 모두 더한 후에 제곱근을 씌워 나타냅니다.
어느 차이를 쓸 지, 혹은 K를 몇으로 설정하는 것이 알맞은지는 데이터셋의 성격과, 여러 가지 변수들에 의해서 달라지므로, 보통 여러 가지 방법을 시뮬레이션 해 본 후에 사용하게 됩니다. (실제 강의중 답변내용)
"KNN 알고리즘은 Training Time 보다 Test Time 이 훨씬 오래 걸려서 Image Classification 에는 적합하지 않다."
Time Complexity
앞에서 이렇게 길게 설명하긴 했지만, 일반적으로 KNN은 Image Classification에 자주 사용되는 모델은 아닙니다. 이는 모델이 가지고 있는 시간복잡도의 비효율성 때문입니다. Image Classification을 효율적으로 실생활에 적용되기 위해서는 Test Time에 그 처리 속도가 빨라야 합니다. 상대적으로 Training Time이 길어지는 문제는 실제로 적용하기 전에 Training을 끝내놓으면 되기 때문에 중요도가 덜합니다.
훈련하는데 100시간이 걸리지만 실제로 적용되어 사용할때는 0.01초 안에 내 이미지의 라벨 값을 알려주는 모델과, 훈련하는 데는 1시간밖에 안걸리지만 실제로 적용되어 사용할 때는 10초 이상 걸리는 모델이 있다고 했을 때, 사용자는 당연히 전자의 모델을 선호할 것입니다.
KNN알고리즘은 훈련시킬때는 단순히 이미지를 기억하고 있으면 되기 때문에 $O(1)$ 의 시간밖에 소요되지 않습니다. ($O(n)$이 아닌 이유는 n개의 훈련 데이터가 있어도 이것이 하나의 벡터로 입력되기 때문에 (n*m*k) 시간을 많이 잡아먹지 않습니다.) 하지만 테스트할 때에는 입력 이미지 하나의 결과를 알기 위해 저장된 모든 이미지와의 거리를 구해야 하기 때문에, $O(n)$ 의 시간이 소요됩니다.
따라서 훈련시간보다 테스트 시간에 연산량이 더 많아지고 시간이 더 오래걸리므로, KNN 알고리즘은 실제로 Image Classification에는 잘 사용되지 않습니다.
KNN알고리즘은 앞으로 다루게 될 CNN알고리즘과는 다르게 픽셀값의 분포나 상대적 위치에 대한 고려가 전혀 없이 단순히 픽셀 값의 차로 이미지의 유사도를 판단하기 때문에 그리 효율적이지 못하다는 단점도 있습니다. 강의 자료에 따르면 아래 4개의 이미지는 모두 L2 norm에 의해 같은 거리를 가지고 있는 이미지라고 합니다.

'Artificial Intelligence' 카테고리의 다른 글
| Principal Component Analysis(PCA) (1) | 2020.04.02 |
|---|---|
| KNN Algorithm with Data-Driven k Value (0) | 2020.04.01 |
| Image Classification Pipeline (0) | 2020.03.28 |
| Markov Decision Process (MDP) (0) | 2020.03.28 |
| Markov Chain (1) | 2020.03.24 |