2020. 5. 10. 13:03ㆍFrontend

친구의 학부논문 연구를 도와주기 위해 웹 크롤링을 사용할 일이 생겨서 Selenium을 사용한 크롤링 개발 후기를 포스팅하게 되었습니다. 크롤링(Crawling)이란, 인터넷상에서 방대한 정보들 중 원하는 정보들을 분석하기 쉬운 형태로 수집하는 것을 의미하며 크롤링을 위해 웹 페이지를 돌며 자료를 수집하는 프로그램을 크롤러(Crawler)라고 합니다.
연구 주제가 '인스타그램과 에브리타임 등 인터넷 플랫폼에서 나타나는 종결어미의 형태변이'에 관한 것이기 때문에 이번에 제작한 크롤러는 에브리타임을 크롤링하며 사람들의 대화 목록들을 수집하고 딥러닝 프레임워크를 이용해서 이를 분석하여 형태 변이가 일어난 종결어미를 포함한 문장들을 필터링하여 텍스트 파일로 저장하는 역할을 수행합니다. 인스타그램을 이용한 크롤러는 다음 포스팅에서 또 따로 다루도록 하겠습니다. 크롤러가 수행하는 기능을 정리하면 다음과 같습니다.
1. 에브리타임 페이지 접속 및 로그인
2. 자유게시판 접속 및 게시글 링크 수집
3. 수집한 링크 방문하면서 게시글과 댓글 수집
4. 수집한 글들을 딥러닝 프레임워크(KoNLPy)를 이용해서 형태소 분석
5. 조건에 맞는 종결어미를 가진 문장들을 필터링
6. 필터링된 문장들을 텍스트파일에 출력
Selenium을 이용한 크롤러
python에서 selenium이라는 프레임워크를 이용하여 크롤러를 개발할 수 있습니다. selenium(이하 셀레니움)은 webdriver의 API를 이용해서 브라우저를 제어할 수 있기 때문에 가상의 크롬을 띄우고 webdriver를 이용해서 DOM을 조작하는 방식으로 크롤링을 진행할 수 있습니다.
webdriver API를 사용하기 위해서는 chromdriver를 로컬에 설치해주어야 하기 때문에 크롬 드라이버 공식 홈페이지에서 다운받아야 합니다. (다운 경로를 잘 지정해주세요. 이 경로를 통해 코드가 크롬 드라이버를 불러오게 됩니다.
기본적인 Python3 세팅과 아래 명령어를 통해 셀레니움을 다운받아주고 (virtualenv를 이용해 가상환경을 만드는 것을 추천드립니다.), 크롬드라이버 공식 홈페이지 링크에서 크롬 드라이버를 설치해 주면 크롤러를 실행하기 위한 기본 환경이 갖추어지게 됩니다.
pip3 install selenium
셀레니움으로 새 크롬창을 열면 기본적으로 incogito(캐시 및 모든 정보가 초기화된 시크릿 탭)으로 열리기 때문에 로그인을 다시 해 주어야 합니다. 창을 열때마다 시크릿탭으로 열기 때문에 창을 열때마다 로그인을 해주어야 하므로, 셀레니움을 통해 에브리타임 게시판에 접속하기 위해서는 우선 로그인하는 과정이 필요합니다.
웹 드라이버를 통해 로그인 URL로 접속하게 되면(driver.get(url)로 접근) 시크릿 탭으로 해당 창이 열리게 됩니다. 여기서 DOM Element를 inspect해서 userId, password에 값을 입력하고 로그인버튼을 찾아 Click 이벤트를 발생시켜 줍니다. 그리고 로그인 된 결과 페이지로 넘어가기 전까지 1초간 기다려 줍니다. (컴퓨터 사양에 따라 1초 이상 기다려야 할 수도 있습니다.) 기다리지 않고 바로 진행할 경우, 페이지가 완전히 로드되기 이전에 DOM Element에 접근하려 하므로 원하는 객체를 찾지 못하거나 에러가 날 수 있습니다.
from selenium import webdriver
driver = webdriver.Chrome('/Users/sangchulkim/Downloads/chromedriver')
driver.implicitly_wait(1)
# go to the login page & login
driver.get('https://everytime.kr/login')
driver.find_element_by_name('userid').send_keys('아이디를 여기에 입력')
driver.find_element_by_name('password').send_keys('비밀번호를 여기에 입력')
driver.find_element_by_xpath('//*[@class="submit"]/input').click()
driver.implicitly_wait(1)
성공적으로 위 코드가 실행되었다면 다음과 같이 로그인된 에브리타임 메인 페이지가 나옵니다.
게시판 url을 찾아 들어간 후에, 각각의 게시판에 있는 게시글들의 링크를 모두 모아서 배열에 저장합니다. 이후 이 배열을 순환하면서 모든 게시물들과 해당 댓글들의 텍스트를 추출하여 results배열에 저장할 것입니다. 배열에 들어있는 링크는 그대로 각각 개별 게시물의 링크를 의미하기 때문에 driver.get을 이용해서 개별 게시물 페이지에 접근할 수 있습니다. 코드는 아래와 같습니다.
# result text files
results = []
cnt = 0 # 첫번째 페이지부터 순환하기 위함.
# go to the list (first page)
while True:
print('Page '+str(cnt))
if cnt > 300: # 나중에 10,000 개로 수정
break
cnt = cnt + 1
driver.get('https://everytime.kr/${게시판 넘버(학교, 게시판마다 다름}/p/'+ str(cnt))
driver.implicitly_wait(1)
# get articles link
posts = driver.find_elements_by_css_selector('article > a.article')
links = [post.get_attribute('href') for post in posts]
# get detail article
for link in links:
driver.get(link)
# get text
comments = driver.find_elements_by_css_selector('p.large')
for comment in comments:
results.append(comment.text)
KoNLPy를 이용한 한글 문장 형태소 분석
앞선 코드로 작성된 크롤러가 실행되고 나면 results 배열에 게시판의 모든 게시글들과 댓글들의 텍스트가 저장됩니다. 이제 이 텍스트를 형태소 분석하여 어미에 'ㅇ'이 붙은 문장들 ('~당, ~행, ~엉"등), 그리고 종결어미가 생략된 문장들('나 ~했', "밥 먹었"등) 을 추출해내야 합니다.
NLP(Natural Language Processin)프레임워크 중 하나이 KoNLPy(KoNLPy의 Okt Class 사용)를 이용하면 한글 문장을 형태소 분석하여 문장의 각각 단어들이 문장 안에서 어떤 역할을 하는지 (동사, 형용사, 명사, 부사...)를 나타내 줍니다. 따라서 저장된 텍스트들을 KoNLPy를 이용해서 형태소 분석을 수행하고, 분석 결과 동사 및 형용사 등으로 분류된 부분들 중 마지막 글자가 ("당", "행", "엉")등으로 끝나는 부분이 있는 문장들을 추출하여 저장하도록 하였습니다.
우선 KoNLPy를 사용해서 예시 문장들을 분석한 코드와 결과는 다음과 같습니다.
from konlpy.tag import Okt
from konlpy.utils import pprint
parserOkt = Okt()
textArr = [
'이렇게 해서 좋당',
'뭐행',
'오늘 뭐했?',
'나는 돈까스가 먹고싶',
'나는 돈까스가 먹고싶엉...',
'보고싶엉 다들 뭐행',
'알겠습니당',
'감사합니당',
'고마워용',
'고마웡',
'귀여웡',
'사랑행',
'알겠어용',
'해주랑',
'졸앗',
'보고싶',
'어렵',
'알겠',
'하겠',
'하겠다'
]
filterArr1 = ['엉', '웡', '당', '양', '넹', '행', '앙', '공', '뎅', '랑', '용', '줭', '깡', '징', '됑', '궁']
filterArr2 = ['겠', '했', '할', '실', '슴', '음', '알', '싶', '렵']
def isValidText1(text):
tuples = parserOkt.pos(text)
for temp in tuples:
# index 0 is word, index 1 is part of speech(pos)
if (temp[1] == 'Verb' or temp[1] == 'Exclamation' or temp[1] == 'Adjective' or temp[1] == 'Noun' or temp[1] == 'Josa'):
if any(condition in temp[0][-1:] for condition in filterArr1):
return True
return False
def isValidText2(text):
tuples = parserOkt.pos(text)
for temp in tuples:
# index 0 is word, index 1 is part of speech(pos)
if (temp[1] == 'Verb' or temp[1] == 'Exclamation' or temp[1] == 'Adjective' or temp[1] == 'Noun' or temp[1] == 'Josa'):
if any(condition in temp[0][-1:] for condition in filterArr2):
return True
return False
result1 = []
result2 = []
for text in textArr:
if (isValidText1(text)):
print('condition1 (ㅇ 붙은 종결어미) = ' +text)
result1.append(text)
if (isValidText2(text)):
print('condition2 (생략된 종결어미) = '+text)
result2.append(text)
print()
결과 textArr에 있는 문장들을 2가지 조건으로 잘 분리하고 있음을 확인할 수 있습니다. 따라서 이 textArr을 앞선 크롤러의 results배열로 대체하면 만족스러운 결과를 얻어낼 수 있습니다.
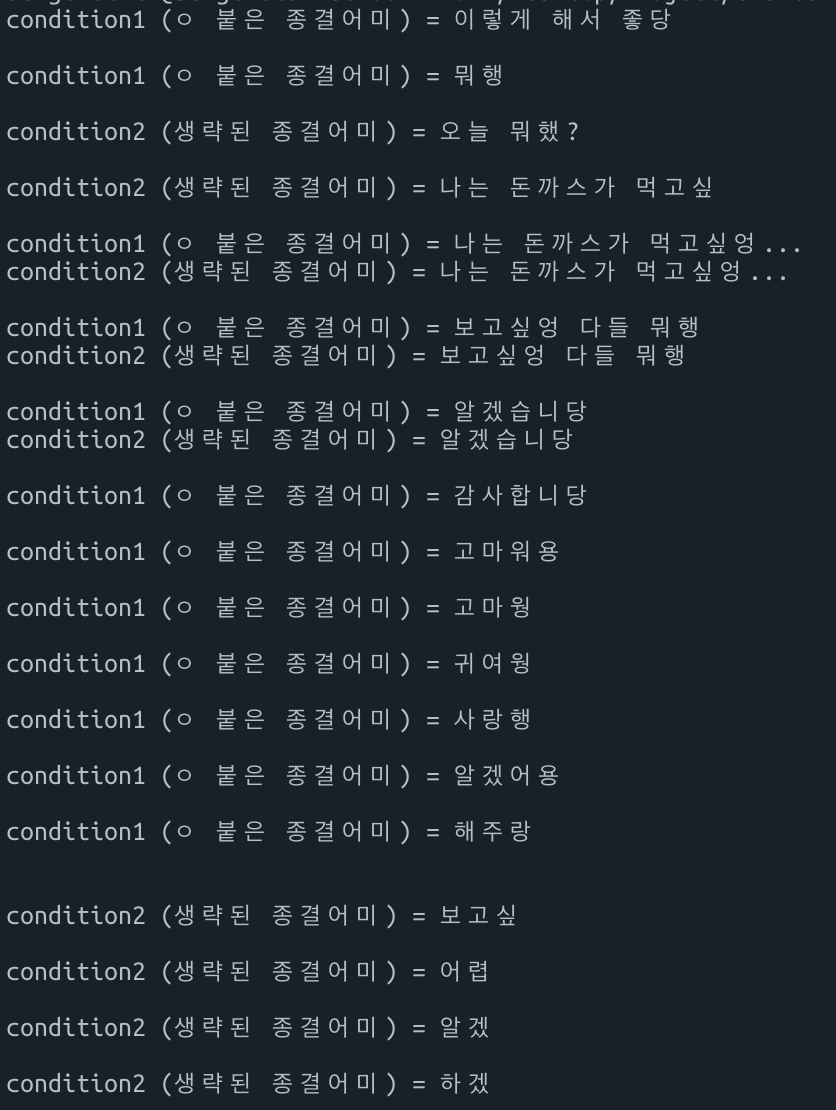
전체 코드
구현된 전체 코드입니다. '종결어미가 생략된 경우' 에 대해서는 조건이 애매한 감이 있어 100%의 정확도로 걸러내지는 못하지만, 빠지는 경우는 없고, '종결어미에 ㅇ이 붙은 경우'는 높은 정확도로 문장을 걸러내고 있음을 확인할 수 있습니다. 다음 포스팅에서는 비슷한 원리도 인스타그램을 크롤링하는 법에 대해서 살펴보도록 하겠습니다.
connect.py
from selenium import webdriver
from konlpy.tag import Okt
from konlpy.utils import pprint
# initializer
parserOkt = Okt()
file1 = open('snu_result1_everytime.txt', 'w')
file2 = open('snu_result2_everytime.txt', 'w')
# filtering Array
filterArr1 = ['엉', '웡', '당', '양', '넹', '행', '앙', '공', '뎅', '랑', '용', '줭', '깡', '징', '됑', '궁']
filterArr2 = ['겠', '했', '할', '실', '알', '싶', '렵', '씀', '있', '맞', '았', '앗', '었', '엇', '햇', '갔', '쉴', '실']
# filtering functions
def isValidText1(text):
tuples = parserOkt.pos(text)
for temp in tuples:
# index 0 is word, index 1 is part of speech(pos)
if (temp[1] == 'Verb' or temp[1] == 'Exclamation' or temp[1] == 'Adjective'):
if any(condition in temp[0][-1:] for condition in filterArr1):
return True
return False
def isValidText2(text):
tuples = parserOkt.pos(text)
for temp in tuples:
# index 0 is word, index 1 is part of speech(pos)
if (temp[1] == 'Verb' or temp[1] == 'Exclamation' or temp[1] == 'Adjective'):
if any(condition in temp[0][-1:] for condition in filterArr2):
return True
return False
result1 = []
result2 = []
driver = webdriver.Chrome('/Users/sangchulkim/Downloads/chromedriver')
driver.implicitly_wait(1)
# go to the login page & login
driver.get('https://everytime.kr/login')
driver.find_element_by_name('userid').send_keys('id')
driver.find_element_by_name('password').send_keys('password')
driver.find_element_by_xpath('//*[@class="submit"]/input').click()
driver.implicitly_wait(1)
# result text files
results = []
cnt = 100
# go to the list (first page)
while True:
print('Page '+str(cnt))
if cnt > 300: # 나중에 10,000 개로 수정
break
cnt = cnt + 1
driver.get('https://everytime.kr/{board number}/p/'+ str(cnt))
driver.implicitly_wait(1)
# get articles link
posts = driver.find_elements_by_css_selector('article > a.article')
links = [post.get_attribute('href') for post in posts]
# get detail article
for link in links:
driver.get(link)
# get text
comments = driver.find_elements_by_css_selector('p.large')
for comment in comments:
results.append(comment.text)
for text in results:
# filter long sentences
if (len(text) > 100):
continue
if (isValidText1(text)):
print('condition1 (ㅇ 붙은 종결어미) = ' +text)
file1.write('condition1 (ㅇ 붙은 종결어미) = ' + text + '\n')
if (isValidText2(text)):
print('condition2 (생략된 종결어미) = '+text)
result2.append(text)
file2.write('condition2 (생략된 종결어미) = ' + text + '\n')
# clear with each loop
results = []
file1.close()
file2.close()
'Frontend' 카테고리의 다른 글
| [OAuth] OAuth 2.0 (0) | 2020.07.04 |
|---|---|
| JIT vs AOT 컴파일러 (1) | 2020.06.16 |
| HTTPS란 (0) | 2020.05.05 |
| Await vs Return vs Return Await (1) | 2020.04.06 |
| CORS 란 (0) | 2020.04.04 |