2020. 4. 27. 22:22ㆍArtificial Intelligence

앙상블 (프랑스어: ensemble)은 전체적인 어울림이나 통일. ‘조화’로 순화한다는 의미이다.
앙상블(Ensemble) 학습이란?
앙상블은 위에 언급된 정의처럼, 여러 성질들을 한데 묶어 조화를 이루게 함으로써 하나로는 도달할 수 없는 어떤 특성에 도달하도록 하는 방법입니다. 주로 합창단, 연주단등 음악에 자주 쓰이는 말이지만, 최근에 머신러닝에서 학습의 효율성을 높이기 위해서 사용하는 방법이기도 합니다. 학습의 정확도가 높은 랜덤 포레스트(Random Forest) 분류기가 이 앙상블 학습을 이용한 대표적인 예라고 할 수 있습니다.
앙상블 학습은 어떤 데이터가 주어졌을 때(분류 문제라고 합시다.), 그 데이터가 어떤 클래스에 속할지를 일련의 예측기(Classifier), 즉 분류나 회귀 모델로부터 예측들을 모아서 결정하는 방식입니다. 아래 그림과 같이 선형 분류기, SVM, 랜덤 포레스트 등 여러 가지 모델들의 예측 결과를 모아서, 가장 가능성이 높은 클래스를 결정하는 것입니다.

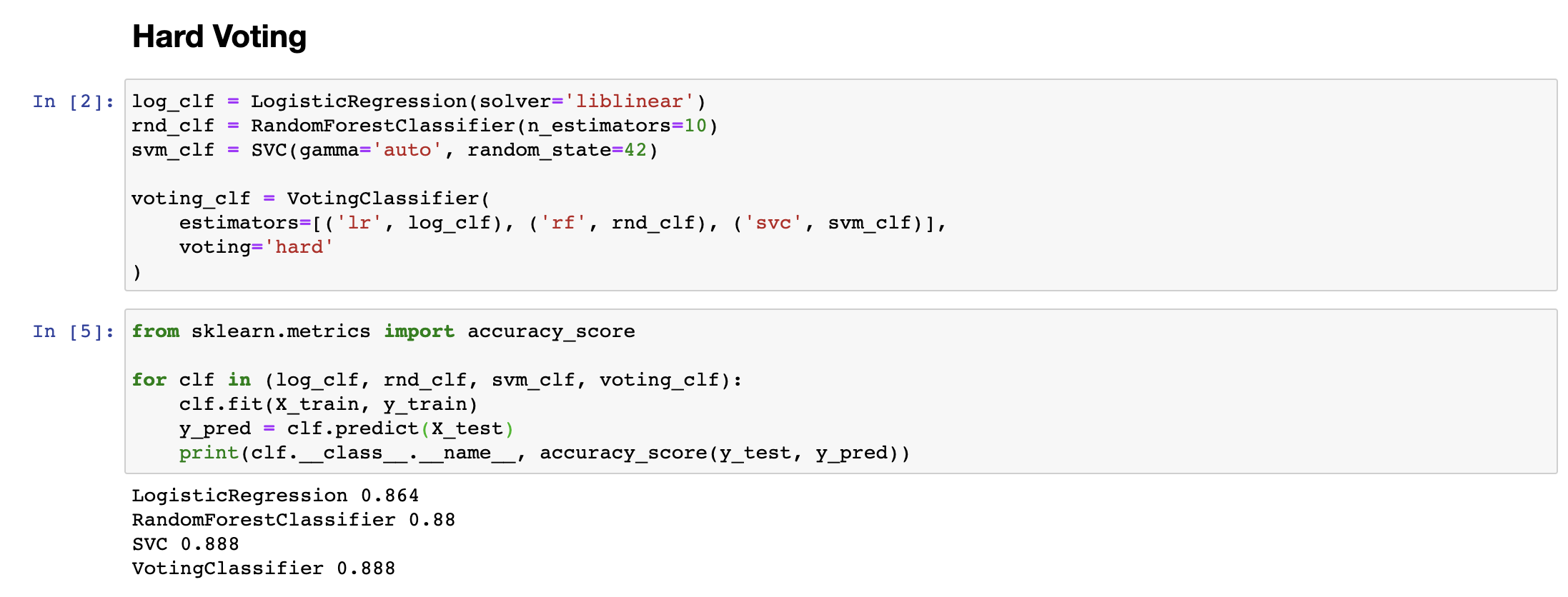
예측 결과를 모아서 가능성이 높은 클래스를 결정하는 방식에는 크게 Hard한 방식과 Soft한 방식 두 가지가 있습니다. Hard한 방식은 흔히 직접 투표(Hard Voting)이라고 불리는데, 여러개의 분류기가 예측한 클래스 중에서 가장 많은 득표(vote)를 얻은 클래스가 앙상블 학습을 적용한 모델의 예측 결과가 되는 방식입니다. 예를 들어 3가지 분류기가 사용되었고, 2가지 분류기가 2번 클래스를, 1가지 분류기가 1번 클래스를 예측했다면, 각각의 분류기가 어느 정도의 확률로 예측했는지와는 상관없이 2번 클래스로 그 결과를 정하는 것입니다.
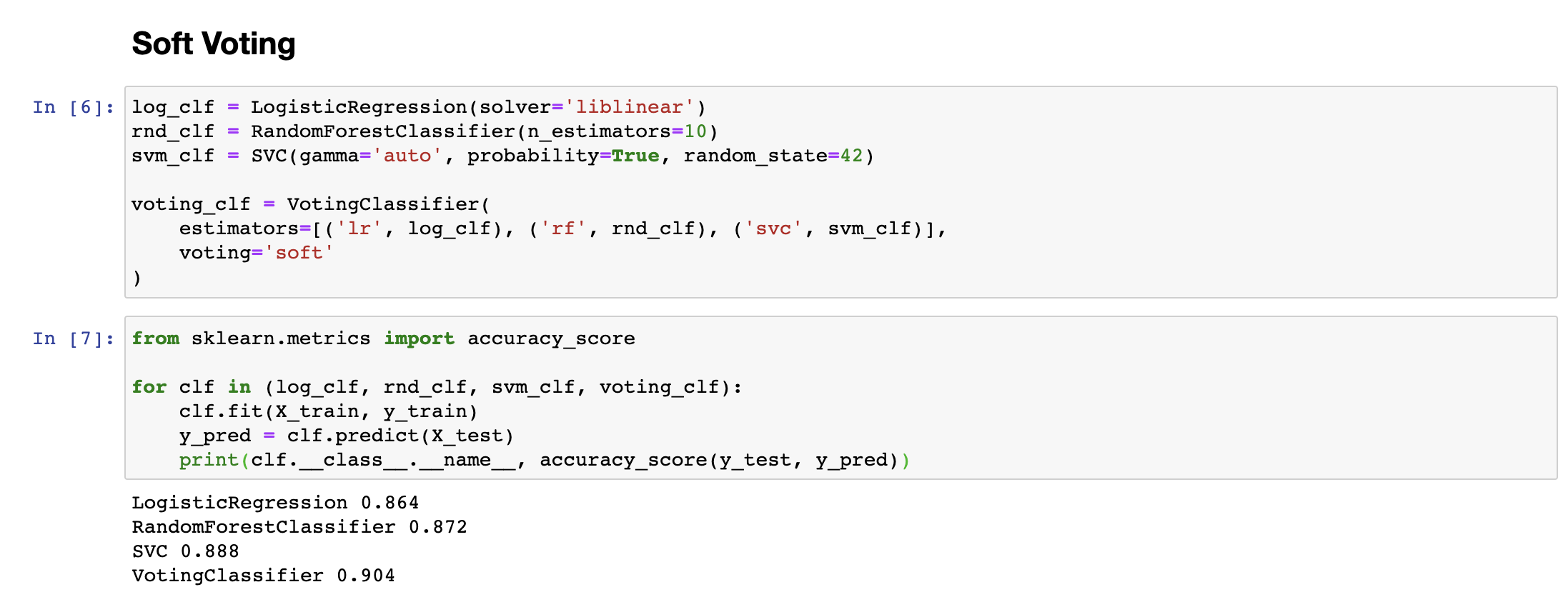
반면 Soft한 방식은 간접투표(Soft voting)이라고 불리며, 여러개의 분류기가 각각 얼마만큼의 확률로 클래스를 예측했는지를 평균내어 결과를 예측합니다. 이 경우에 특정 클래스의 확률을 높게 예측한 경우, 해당 분류기에 더 가중치가 붙게 되므로, 더 정확한 예측이 가능하다는 장점이 있습니다. 아래 실험결과를 보면, Soft Voting의 경우, Hard Voting보다 결과가 더 정확한 것을 확인하실 수 있습니다.
왜 앙상블인가?
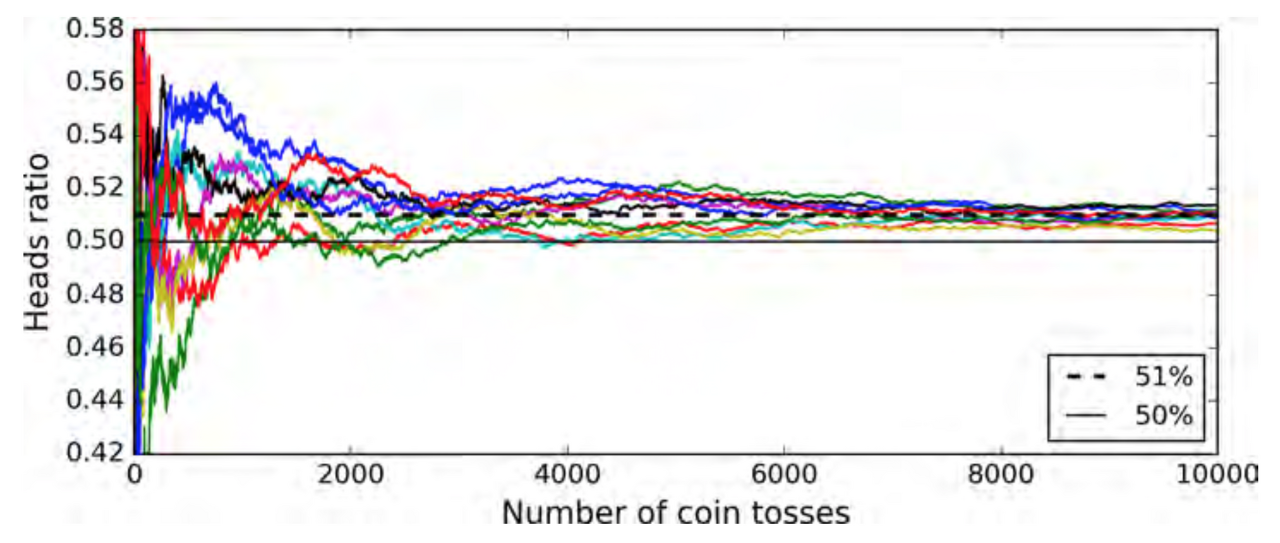
앙상블 학습을 사용하는 이유는, 앞서 언급한 것과 같이 개별 분류기보다 여러 분류기들의 예측을 합친 것이 더 정확하기 때문입니다. 이는 큰 수의 법칙(Law of Large Numbers)때문인데요, 예를 들어 앞면이 나올 확률이 51%인 조금 불균형한 동전이 있다고 가정하겠습니다. 이 동전을 1000번 던졌을 때, 앞면이 절반 이상 나올 확률은 75%가 넘는다는 것은 다항 분포를 통해 확인할 수 있습니다.
동전을 이진 분류기로 바꾸어 다시 생각해 보면, 51%의 정확도를 가진 분류기 하나는 1개의 예측에 대해 51%의 정확도밖에 보여주지 못하지만, 이런 분류기를 1000개 모아서 다수결로 예측결과를 모아서 예측하게 되면, 그 정확도가 75% 가까이 된다는 것입니다. (10000개 이상의 데이터에 대해서는 97% 이상의 정확도를 보여줍니다.) 따라서 앙상블 학습(분류기를 많이많이 모아 예측하는 것)은 하나의 분류기의 결과보다 높은 정확도를 보여줄 것이라고 기대할 수 있습니다.
물론 이항 분포는 모든 시행이 독립이라고 가정하지만, 실제로 모든 분류기가 독립이 될 수는 없으므로 이상적으로 동전 던지기와 완전히 동일하다고는 볼 수 없지만, 여러 가지 조정을 통해 예측을 독립과 비슷한 상태로 최대한 만들어 예측할 수 있습니다.
배깅과 페이스팅
앙상블 학습을 위해서는 다양한 분류기가 필요합니다. 이때 다양한 분류기를 만드는 방법에는 다양한 알고리즘을 사용하는 방법(Linear Regression, SVM, Random Forest.. etc)도 있지만, 같은 알고리즘을 사용하면서 훈련 세트의 서브셋을 무작위로 구현하여 분류기를 다양하게 학습시키는 방법도 있습니다. 이때 사용되는 방법이 바로 배깅(Bagging)과 페이스팅(Pasting)입니다.
훈련 세트에서 중복을 허용하여 샘플링하는 방식을 배깅(bootstrap aggregating)이라 하고, 중복을 허용하지 않고 샘플링하는 방식을 페이스팅(Pasting)이라고 합니다. 배깅이나 페이스팅 방식을 사용하면, 동일한 분류기를 다양한 데이터셋으로 훈련시키므로, CPU코어나 여러 대의 서버에서 병렬 연산으로 훈련이 가능하다는 장점이 있습니다.
아래 코드는 사이킷런을 통해서 배깅과 페이스팅을 테스트한 결과입니다. bootstrap=True로 설정하면 배깅 방식으로 샘플링하여 훈련하게 되고, False로 설정하면 페이스팅 방식으로 샘플링하여 훈련하게 됩니다. 앙상블 학습 방법은 비슷한 편향에서 더 작은 분산(비록 편향은 더 크지만)을 만들어서, 결정 경계가 덜 불규칙한 모습을 띕니다.

'Artificial Intelligence' 카테고리의 다른 글
| ImageNet Classification with Deep Convolutional Neural Networks (AlexNet) - 2012 (0) | 2021.10.04 |
|---|---|
| [FSDL] CNNs (0) | 2021.10.01 |
| [RandomForest] 랜덤 포레스트란? (0) | 2020.04.27 |
| [RNN] Vanila RNN을 이용한 SPAM Filter구현 (0) | 2020.04.19 |
| [SVM] SVM으로 MNIST 분류하기 (0) | 2020.04.18 |