2020. 4. 18. 16:15ㆍArtificial Intelligence

서포트 벡터 머신(Support Vector Machine: 이하 SVM)은 Classification 문제에서 결정 경계(Decision Boundary)를 효율적으로 찾는 방법을 제공합니다. 즉, 아래 그림과 같이 두 클래스(빨강, 초록)로 분류될 수 있는 데이터 셋이 있다고 했을 때, 이 데이터셋을 가장 잘 구분 짓는 경계선(실선)을 찾는 것입니다. 이번 포스팅에서는 SVM을 이용해서 MNIST Dataset Classification을 개선해보려 합니다. (Application에 관한 글이므로 SVM의 수학적 원리와 기타 증명 과정은 생략하였습니다.)
지난 MNIST 포스팅 에서는 Random Forest를 이용해 간단한 MNIST 분류 모델을 만들었습니다. 이번에는 SVM을 이용해서 MNIST 분류 모델을 만들어보고자 합니다. MNIST 데이터셋은 모든 Input이 0~255 사이의 픽셀 값이므로 따로 polynomial한 Feature들을 추가하지 않고 Linear Model을 사용하여 분류하였습니다.
Scikit Learn은 LinearSVM을 구현하는 2가지 방법을 제공합니다. 둘다 Linear SVM 모델을 구현할 수 있는 방안을 제공하지만 내부 구현 및 time complexity등의 차이가 있어서 이 둘을 적절하게 사용하는 것이 중요합니다.
from sklearn.svm import LinearSVC
# usage
LineaerSVC().fit(X, y)
from sklearn.svm import SVC
# usage
SVC(kernel='linear').fit(X, y)
LinearSVC
- Hinge Loss의 제곱한 값을 최소화합니다.
- 다중 클래스 분류 방법 중에 ('One vs Rest')방법을 선택하므로 N개의 클래스가 있다고 할 때, N개의 모델을 생성합니다.
- sklearn의 estimator중 liblinear을 사용합니다.
이는 선형 분류에 최적화되어 있으므로 선형 데이터 분류에서 빠른 속도를 냅니다.
SVC
- Hinge Loss 자체의 값을 최소화합니다.
- 다중 클래스 분류 방법 중에 ('One vs One')방법을 선택하므로
N개의 클래스가 있다고 할 떄 N * (N-1) / 2개의 모델을 생성하므로 Linear SVC보다 시간이 더 오래 걸립니다.
- sklearn의 estimator중 libsvm을 사용합니다.
이는 선형 분류뿐만 아니라 여러 kernel들을 지원하므로 선형 데이터 분류에 최적화되어 있지는 않습니다.

데이터셋을 불러와서 train_test_split 메서드를 사용하여 Training Set과, Test Set 을 분류해 줍니다. 이 단계는 이전 MNIST 포스팅과 동일합니다.
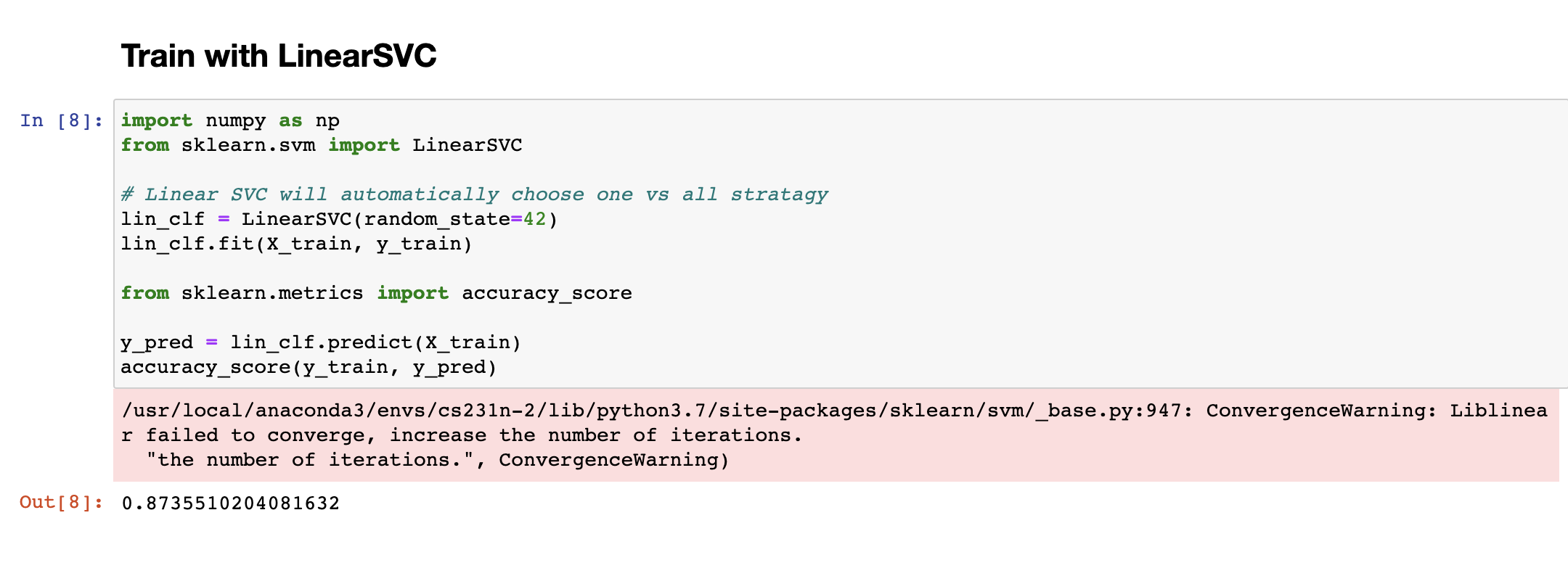
LinearSVC 모델을 아무런 전처리 없이 한번 실행한 결과 Training Set에서 87.3% 정도의 정확도를 보이는 것을 알 수 있습니다. 지난 RandomForest Classifier를 사용했을 때 Cross Validation Set에서 97% 정도의 정확도를 보였던 것과 비교하면 성능이 좋아보이지는 않습니다.
SVM은 Feature Scale에 민감하게 영향을 받는 모델 중의 하나입니다. 왜냐하면 결정 경계를 정하는 과정에서 어느 한 특징이 다른 특징보다 훨씬 큰 스케일을 갖게 되면, 그 두 특징 사이에 형성되는 기울기 자체가 무의미해지고 결국 스케일이 작은 특성이 완전히 무시되기 때문입니다.
MNIST데이터의 경우에는 데이터의 값 자체는 0~255로 균일하지만 Feature가 784개나 있고, 그 중에 실제로 글씨가 쓰여지는 구간은 높은 값들을 갖는 반면, 글씨가 쓰여있지 않는 가장자리 부분은 거의 대부분 0에 가까운 값들을 갖고 있기 때문에 Feature Scale을 하지 않으면 해당 Feature들이 무시되어 부정확한 결과를 가져오는 것입니다.

따라서 StandardScaler를 통해 데이터 스케일링을 한번 해주고 다시 학습을 진행합니다. 이 경우 92.6%로 기존보다 훨씬 더 정확한 값을 가져오는 것을 확인할 수 있습니다. RandomSearch 나 GridSearch를 이용해서 적절한 하이퍼 파라미터를 넘겨준다면 97%에 가까운 정확도를 달성할 수 있습니다.

SVM 모델도 학습 방법은 LinearSVM모델과 동일합니다. 다만, SVM모델은 앞서 언급한 바와 같이 One vs One의 전략을 취하기 때문에 LinearSVM 모델의 학습보다 시간이 훨씬 더 오래 걸린다는 단점이 있습니다.
RandomSearch를 통해 최적의 하이퍼파라미터를 찾을 수 있도록 설계하였고, 훈련 결과, Training Set에서 99.9%, Test Set에서 97%에 가까운 정확도로 숫자를 분류해 내는 것을 확인할 수 있습니다.



'Artificial Intelligence' 카테고리의 다른 글
| [RandomForest] 랜덤 포레스트란? (0) | 2020.04.27 |
|---|---|
| [RNN] Vanila RNN을 이용한 SPAM Filter구현 (0) | 2020.04.19 |
| [SPAM FILTER] 간단한 스팸 분류기 (1) | 2020.04.15 |
| [TITANIC] 타이타닉 생존자 예측 모델 (0) | 2020.04.14 |
| [MNIST] Random Forest를 이용한 간단한 모델 만들기 (0) | 2020.04.12 |